
On a recent project, we were tasked with developing a series of eLearning modules on using statistical data and processing gender data in order to reach sustainable development goals. For the training content, we utilized the training curriculum written by the experts in the field of data and statistics provided by UN Women. The resulting eLearning course consists of 10 modules and covers the materials that many data and statistics professionals will find helpful, especially those who facilitate trainings on the topic and are particularly interested in the subject of gender statistics.
The Target Learner for Gender Statistics eLearning
The curriculum is aimed at a wide array of data and statistics professionals, including:
Statisticians and other experts who wish to understand what gender statistics are and how these can be integrated across different areas of statistics.
Policymakers and decision-makers who are looking to enhance their use of gender data for evidence-based decision-making.
Academicians who wish to focus or inform their research through the use of gender data.
Civil Society organizations who wish to enhance their use of gender data for advocacy or communication purposes.
Journalists and media personnel interested in integrating gender data into their media products and presenting a more accurate and comprehensive picture
Anyone who wishes to find out what gender data is and how to use it.
The Sustainable Development Goals
Before reading any further about the gender statistics eLearning modules we developed, it is important to understand the reason it’s vital to provide quality training on working with statistical data. Here’s some background.
The 2030 Agenda for Sustainable Development, adopted by all United Nations Member States in 2015, provides a shared blueprint for peace and prosperity for people and the planet, now and into the future.
This Agenda is a plan of action for people, the planet, and prosperity. It also seeks to strengthen universal peace in larger freedom. The Agenda recognizes that eradicating poverty in all its forms and dimensions, including extreme poverty, is the greatest global challenge and an indispensable requirement for sustainable development. All countries and all stakeholders acting in collaborative partnership will implement this plan.

At the heart of the 2030 Agenda for Sustainable Development are the 17 Sustainable Development Goals (SDGs) which are an urgent call for action by all countries – developed and developing – in a global partnership. They recognize that ending poverty and other deprivations must go hand-in-hand with strategies that improve health and education, reduce inequality, and spur economic growth – all while tackling climate change and working to preserve our oceans and forests. These goals are:
Goal 1. End poverty in all its forms everywhere.
Goal 2. End hunger, achieve food security and improved nutrition, and promote sustainable agriculture.
Goal 3. Ensure healthy lives and promote well-being for all at all ages.
Goal 4. Ensure inclusive and equitable quality education and promote lifelong learning opportunities for all.
Goal 5. Achieve gender equality and empower all women and girls.
Goal 6. Ensure availability and sustainable management of water and sanitation for all.
Goal 7. Ensure access to affordable, reliable, sustainable, and modern energy for all.
Goal 8. Promote sustained, inclusive, and sustainable economic growth, full and productive employment, and decent work for all.
Goal 9. Build resilient infrastructure, promote inclusive and sustainable industrialization, and foster innovation.
Goal 10. Reduce inequality within and among countries.
Goal 11. Make cities and human settlements inclusive, safe, resilient, and sustainable.
Goal 12. Ensure sustainable consumption and production patterns.
Goal 13. Take urgent action to combat climate change and its impacts.
Goal 14. Conserve and sustainably use the oceans, seas, and marine resources for sustainable development.
Goal 15. Protect, restore and promote sustainable use of terrestrial ecosystems, sustainably manage forests, combat desertification, and halt and reverse land degradation and halt biodiversity loss.
Goal 16. Promote peaceful and inclusive societies for sustainable development, provide access to justice for all, and build effective, accountable, and inclusive institutions at all levels.
Goal 17. Strengthen the means of implementation and revitalize the Global Partnership for Sustainable Development.
The Training Focus on Gender Data and Gender Statistics
The SDGs are universal and integrated, relevant to all people everywhere. However, it is impossible to reach the goals without ensuring that women who make half of the world population are not left behind. Assessing how women and girls are doing in relation to the SDGs starts with identifying the relevant SDG targets and indicators and the data available to monitor achievements are vital tasks. While some of the 169 targets refer to issues that concern society as a whole and the planet, others relate to individuals, such as reducing malnutrition rates, where achievements may differ between women and men. Additionally, some targets are explicitly focused on women, such as on reducing maternal mortality.
In committing to the realization of the 2030 Agenda for Sustainable Development, the UN Member States recognized that the dignity of the individual is fundamental, and that the Agenda’s Goals and targets should be met for all nations and people and all segments of society. Furthermore, they endeavored to reach first those who are furthest behind.
Ensuring that these commitments are translated into effective action requires a precise understanding of target populations. However, the disaggregated data needed to address all vulnerable groups – including women, children, youth, persons with disabilities, people living with HIV, older persons, indigenous peoples, refugees, internally displaced persons, and migrants – as specified in the 2030 Agenda, are sparse. For this reason, focusing specifically on statistical data related to a vulnerable group will ensure that the needs of this group are being recognized.

eLearning Module 1: What Is Gender Data and How to Use It for SDG Monitoring
Module 1 of the eLearning course is an introductory module on gender statistics targeted to both experts and non-experts. No advanced knowledge of statistics is necessary to complete the eLearning. However, it would be good for the learner to have an idea of what the Sustainable Development Goals (SDGs) are, including their targets and indicators.

After going through the first module, the learner is expected to become familiar with the concepts of sex and gender and understand the multidisciplinary nature of gender statistics. The module also provides an introduction to gender indicators, particularly in the context of monitoring the SDGs. Therefore, the learner is expected to gain knowledge on how gender statistics can help monitor the SDGs from a gender angle, in the spirit of inclusiveness. Finally, trainees are presented with a brief introduction to some key reasons behind the lack of availability of gender statistics for SDG monitoring in Asia and the Pacific, and recommendations on how to overcome these challenges.
Gender statistics are defined as statistics that adequately reflect differences and inequalities in the situation of women and men in all areas of life. Gender statistics are the sum of the following characteristics:
- Data are collected and presented with disaggregation by sex;
- Data reflect gender issues;
- Data are based on concepts and definitions that adequately reflect the diversity of women and men and capture all aspects of their lives; and
- Data collection methods take into account stereotypes and social and cultural factors that may induce gender biases.
Generally, gender statistics can include:
- Sex-disaggregated data
- Data pertaining specifically to women or men
- Data that capture specific gender issues – even when these issues do not necessarily mention gender, sex, or women and men explicitly

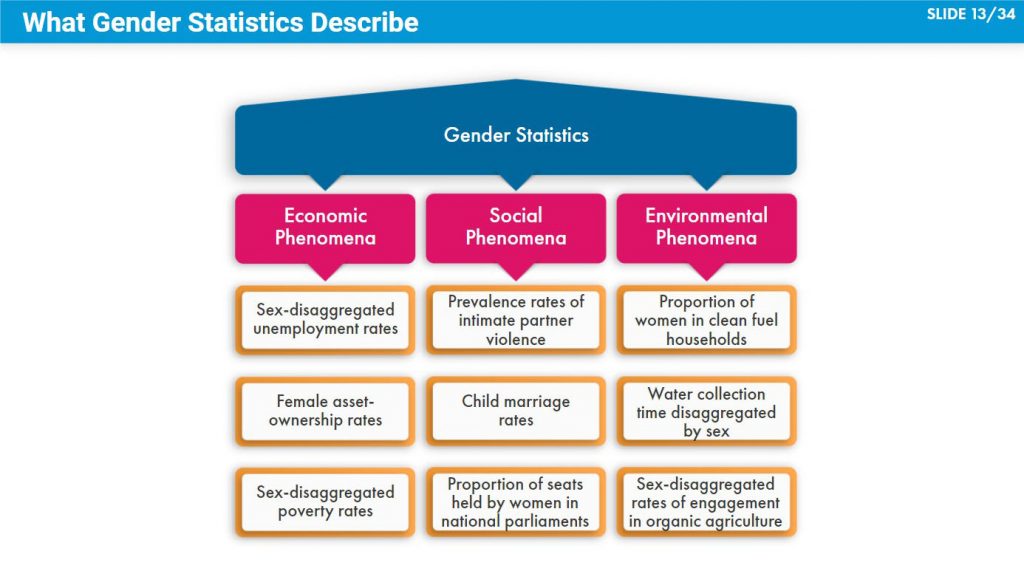
There are gender statistics that describe economic phenomena (e.g. sex-disaggregated unemployment rates, female asset-ownership rates, and sex-disaggregated poverty rates.), social phenomena (e.g. prevalence rates of intimate partner violence, child marriage rates, and proportion of seats held by women in national parliaments.) and environmental phenomena (e.g. proportion of women living in households that rely on clean fuels, average time spent on water collection disaggregated by sex, and sex-disaggregated rates of engagement in organic agriculture and farming practices).
Are gender statistics the same as gender data? Generally, after statisticians compile, manage, and analyze raw data, they generate statistics. Therefore, the concept of statistics, technically speaking, refers to numerical data that have been manipulated to generate estimates for a particular country, year, and/or population group.
For instance, while the process of birth registration might result in a set of data on the individual characteristics of newborns, sex-disaggregated birth registration rates for a certain country are statistics derived from these data. In practice, however, people often refer to gender statistics and gender data interchangeably for ease of reference.
Indicators, on the other hand, are a quantitative metric that provides information to monitor performance, measure achievement, and determine accountability. Gender indicators, therefore, are tools for measuring gender inequalities or gender-specific issues. The use of gender indicators is essential to measure progress achieved towards various forms of commitments – from national strategies and policies to global agreements such as the 2030 Agenda – in an inclusive manner. Some indicators specifically mention sex-disaggregation. Therefore, data produced for this indicator will qualify as gender statistics. It is often the case that data can be further disaggregated beyond just one dimension. In the example shown here, the data have also been disaggregated by marital status to capture the situation of single mothers. These data, too, are gender statistics.
Besides the gender indicators, it is important to keep in mind that, although many SDG indicators do not explicitly mention sex-disaggregation, many should still be sex-disaggregated and have the potential to produce significant results from a gender perspective.
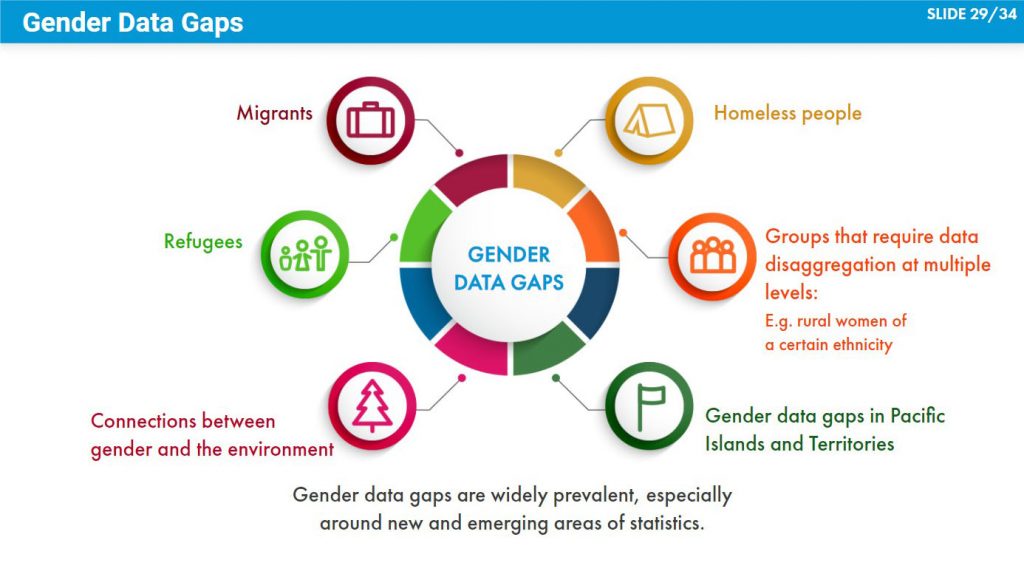
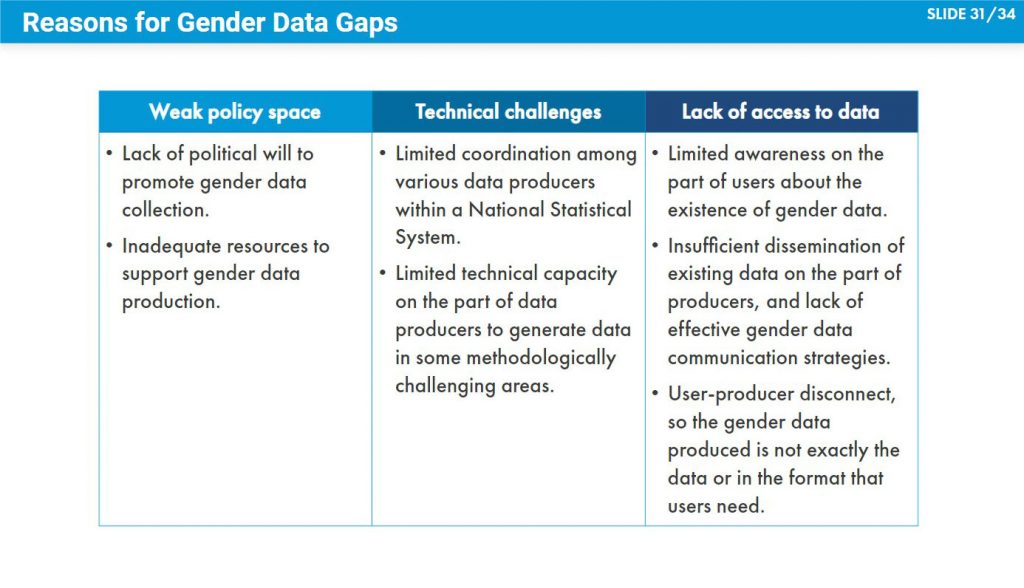
Gender data gaps are widely prevalent, especially around new and emerging areas of statistics, such as those that capture the connections between gender and the environment, as well as around population groups that are hard to reach, such as refugees, migrants, homeless people, and vulnerable groups that require data disaggregation at multiple levels (e.g. rural women of a certain ethnicity). Geographically, in Asia and the Pacific, gender data gaps are especially prevalent in the Pacific Island Countries and Territories, although for select indicators they are pervasive across the region. To fill gender data gaps, it is important to understand the most common reasons behind such gaps. These may include the following:
- Weak policy space
- Technical challenges
- Lack of access to data
To summarize this eLearning module, it’s important to note that gender data is essential to make informed decisions. The use of gender statistics is of utmost importance to achieve the SDGs for all. Going beyond national averages – including through using gender data – is important to meet the promise of Leaving No One Behind.
eLearning Module 2: Gender Data Literacy and Avoiding Common Mistakes in Interpreting Gender Data
This module talks about:
- The key concepts of data and statistics as well as the differences between the official and non-official statistics and when it’s appropriate to use each one.
- Calculation of ratio, rate, proportion, percentage, percentage points, mean, median, and other values of an indicator.
- Common mistakes in interpreting gender data and how to avoid making these mistakes.
Official statistics are statistics produced either by the national statistics office or another government body in charge of data production (for example, a line ministry, central bank, or national meteorology agency, etc.). They are usually produced in accordance with the National Statistics Law/Act and in line with the fundamental principles of official statistics. In select cases, official statistics might also be produced by third-party organizations, such as private sector entities, civil society organizations, or academic institutions, with the involvement of the national statistics office or other national statistical authority. It is important to note that, in these cases, the national statistics office’s involvement and validation of such statistics are essential for the figures to be treated as official.
Some examples of official statistics include:
- Figures derived from census data
- Estimates derived from official surveys
- Aggregates calculated using administrative records compiled by government institutions (for example, birth registration)
- Increasingly, select official statistics are also starting to be produced using non-conventional sources (for example, big data, crowdsourcing, etc.)
Non-official statistics are those produced without any involvement of the national statistical office or any other member of the national statistical system. These statistics are often narrower in coverage, as sample sizes tend to be larger in data collection exercises conducted by national statistical authorities (due to the availability of financial and human resources for data collection). While most official statistics tend to be produced periodically (for example, the population and housing census typically takes place once a decade and demographic surveys often have a five-year periodicity), non-official statistics are more likely to be in the form of ad-hoc studies and one-off data collection experiments.
Official statistics are almost always preferable over non-official statistics, as they are usually more comprehensive, and their periodicity tends to be more frequent. This is often the case because:
- National statistical systems have larger financial resources allocated to data collection.
- Official data producers are able to make use of census data for sampling purposes, resulting in more accurate estimates.
- NSOs and other producers within NSSs for whom data production is a core responsibility are able to access and train large numbers of enumerators, who are well prepared to collect data; and
- Most official statistics tend to be produced at regular intervals as funds are allocated accordingly by national governments.
There are, however, two instances when non-official statistics might be preferable: firstly, when the user is looking for data on a particular topic that might not be available through official statistics, and secondly when data is needed on more sensitive topics such as on government corruption, good governance, etc.
Another important concept here is metadata. Metadata refers to the range of information, generally textual, that fosters an understanding of the context in which statistical data have been collected, processed, and analyzed with the objective of creating statistical information (for example, legal and regulatory information, methods and concepts used at all levels of information processing, definitions, nomenclatures, etc.). In other words, metadata is information about data. Metadata might provide information about an indicator, a data series, or a data point. Generally, for monitoring the Sustainable Development Goals, two types of metadata are used: indicator/series metadata and data point metadata. Metadata makes data meaningful.
Firstly, without metadata, we would not be able to understand the data. For instance, look at the data table shown here. Would you be able to understand what it refers to? Without the appropriate metadata, which in this case is the name of the indicator, the definition of the indicator, and the unit of measurement, the data is meaningless.
Secondly, metadata improves the comparability of data. Differences in data and their interpretation can arise due to the use of different definitions, concepts, units, and classifications. When comparing data between countries or across time, make sure to look at the metadata fully for any inconsistencies or changes that may have taken place over time. For instance, in the case of child marriage, two different indicator series might be produced – girls married or in union before age 15 and girls married or in union before age 18. Metadata is important to understand the age range being considered.
And thirdly, metadata can provide information about inconsistencies in computation methods. For instance, the Sustainable Development Goals SDG indicator 3.7.2 on adolescent birth rates is defined as the annual number of births to females aged 15 to 19, per 1,000 females in the respective age group. The metadata for this indicator, however, clarifies that depending on the type of data source used to calculate this indicator, the method of computation differs. This information is important to understand any possible discrepancies in estimates over time.
Internationally agreed definitions exist for almost all statistical concepts. When new indicators are developed, the obtention of the international agreement on definitions is often the first step towards data production. The use of such definitions ensures the international comparability of the data. For Sustainable Development Goals indicators, these definitions and classifications can be found in the SDG metadata repository. When interpreting data, they must be kept in mind.
Another concept or term we need to understand is data. Data are measurements or observations that are collected as a source of information. There are a variety of different types of data and different ways to represent data. In statistical circles, two main types of data are used: macrodata and microdata. Typically, both macrodata and microdata are stored in databases, online repositories, and data servers. While macrodata is often openly available online, accessing microdata might sometimes entail submitting a formal request and signing a confidentiality agreement.
Finally, in statistics, a variable is another term used all the time. A variable is any factor that is capable of having multiple values.
When it comes to calculations, this eLearning module goes into details about calculating and using ratio, rate, proportion, percentage, and percentage points as well as mean, median, average, and total when working with gender data.
The module goes over several misinterpretation issues specific to gender data. Namely:
- Interviewing only the household heads
- Measuring gender gaps
- Measuring violence and crime
- Measuring time use of women and men
- Sex-disaggregated poverty rates
- Measuring and interpreting the gender pay gap
eLearning Module 3: Calculating Gender Statistics for SDG Monitoring

This module teaches the learners to:
- Recognize how gender-specific analysis is possible by disaggregating the data by sex even if it is not a gender-specific indicator.
- Understand the key concepts and methods of computation of the indicators.
- Understand gaps and challenges in terms of indicators and data availability for an emerging area of statistics.

Fulfilling the 2030 Agenda for Sustainable Development requires accelerated change. Since women and girls are often the furthest behind, effective monitoring of women’s progress across all SDGs is crucial to fulfilling this agenda. Gender mainstreaming is needed across all three pillars of sustainable development: economic, social, and environmental development. The global SDG indicator framework was designed to monitor progress across these three pillars. Gender is relevant for all three pillars and must be integrated when measuring progress either by disaggregating by sex where relevant or specifically taking into consideration issues relevant for men, women, girls, and boys.
A gender perspective needs to be integrated when calculating SDG indicators across all goals. Each country should select indicators according to national priorities and needs. It is important to keep in mind, however, that data disaggregation can and should be performed even for SDG indicators that do not necessarily include disaggregation by sex in the official indicator description.

The links between gender and the environment are not well understood and gaps in data availability impede progress assessment on the environmental dimension of sustainable development. Substantial gaps exist in understanding the gender-environment nexus issues as well as in terms of indicators and data availability to measure this relationship between gender and the environment. Through recent work and consultations (since 2019) between international agencies, disaster management agencies, national statistical offices (NSOs), and other government and academic bodies, some key priority areas to measure these connections in Asia and the Pacific have been identified.

The SDGs have a total of 93 environmental indicators as of early 2020, most of which lack a gender perspective. In 2019, the United Nations Environment Programme (UNEP) and the International Union for Conservation of Nature (IUCN) identified a list of 19 indicators that could be used to measure the connections between the environment and gender. Besides those 19, and the additional environment-gender indicators in the SDG global indicator framework, experts in the Asia-Pacific region highlighted the need to expand the set of indicators to better understand the environment-gender nexus.

eLearning Module 4: User-Producer Dialogue
The module on user-producer dialogue enables the learners to:
- Know the differences between data users and data producers and their respective roles as well as understand the importance of effective user-producer engagement.
- Understand the steps to conduct a successful user-producer dialogue.
- Become familiar with good practices and tips for the success of a user-producer dialogue.
In a data ecosystem, various actors interact to produce, exchange and consume data. These are complex as in any given country, there might be a large number of data producers, who may or may not be coordinating amongst themselves, and also a large number of data users.
Data producers are usually referred to as organizations in charge of generating data. In the context of producing gender statistics, including for monitoring of the Sustainable Development Goals, data producers include national statistical offices. Data producers also include line ministries, other government departments, some international organizations, and, in some instances, the private sector and civil society organizations that generate statistics.
Data users are consumers of data. The most common users of gender-related data include policymakers from ministries like I represent, other decision-makers, government bodies, civil society organizations, academics and researchers, private-sector institutions, media as well as international organizations.
Adaptation to user’s needs should be both policy- and format-based. As policy priorities change over time, so do data needs. For instance, producing environment statistics from a gender perspective to better capture how women and men contribute to environmental management and degradation differently, is now much more relevant than it was a decade ago in view of the accelerated impact of climate change. User-producer dialogue can enable stakeholders to discuss their work programs so that data demands can be anticipated and responded to in a timely manner. With the development of new technologies and the evolution of education systems, users today might be able to consume data in different formats compared to the past. For instance, communicating data via social media is now an effective way to reach the general public, but this channel did not really exist in the past. Dialogue is also relevant to ensure the data produced fits the technical skills of stakeholders and is used efficiently.
User-producer engagement can generate trust on both sides. It is in the interest of data producers of official gender statistics to provide trusted, impartial and accurate information to users. With the increasing availability of ad-hoc studies and non-official statistics, it might be difficult for users to evaluate the quality of gender data and to differentiate accurate data from misleading statistics. Long-term engagement between users and producers can help data users understand the differences in quality between different data sources and understand the limitations of existing sources. Similarly, engagement can build the trust of producers on groups of users and the way they intend to use microdata and/or sensitive data.
Here are some key decision points in the user-producer dialogue:
- Identify data users’ needs, from a thematic point of view and from a technical perspective.
- Elucidate data producers’ capacity and limitations to respond to users’ needs.
- Share information about calendars of releases, available data, where to find it, how to interpret it, its caveats, and who to get in touch with should additional questions arise.
- Whether a formal mechanism needs to be either established or improved to ensure dialogue continues consistently over time.
Overall, this dialogue should result in better alignment of data users and producers’ priorities and support the establishment of connections and communication flows.
Besides institutionalizing the dialogue process, other forms of collaborative agreements can be set up. For instance, on the production or use of gender data. For gender data production, during the dialogue, it is important to assess if the existing data production processes and institutions are yielding the desirable data and results.
Here are the steps for organizing a gender statistics user-producer dialogue:
- Step 1: Meet-Up
- Step 2: Review
- Step 3: Meet Again
- Step 4: Debrief
- Step 5: Reporting
- Step 6: Meet Again
Although user-producer dialogues often result in reinforced communication channels, enhanced data production and use, and better alignment of users and producers’ needs, there might be some drawbacks associated with conducting these dialogues.
Coordination among data producers is essential to maintain consistency in the statistics produced and to avoid overlapping data production activities. At the same time, regular and systematic engagement and dialogue between data producers and data users is critical in order for data producers to generate statistics that meet the needs of users, and for users to understand what statistics are available, where to find them, whether they are fit for purpose, and how to influence production based on their needs.
eLearning Module 6: Analyzing Microdata with a Gender Angle
This module on analyzing microdata with a gender angle has the following learning objectives:
- Be able to understand the different types of data sources used for gender analysis.
- Learn about the strengths and weaknesses of each data source introduced in this module.
- Know how to prepare the dataset and understand the sampling design and weighting scheme.
- Be able to create cross-tabulations as well as understand and interpret the cross-tabulated data.

Gender data are collected through various types of data sources:
- Household surveys
- Dedicated surveys
- Censuses
- Administrative records
- Other sources
Throughout the module, we work with data from the Multiple Indicator Cluster Survey (MICS) and the question on attitudes towards domestic violence in MICS. To understand the underlying factors that contribute to the formation of attitudes towards domestic violence, further analysis needs to be performed. To demonstrate each step involved in analyzing gender data, we investigate factors that influence the attitudes towards domestic violence by analyzing MICS6 data from Mongolia. Country specific MICS6 datasets can be accessed for completed surveys at the official MICS website.
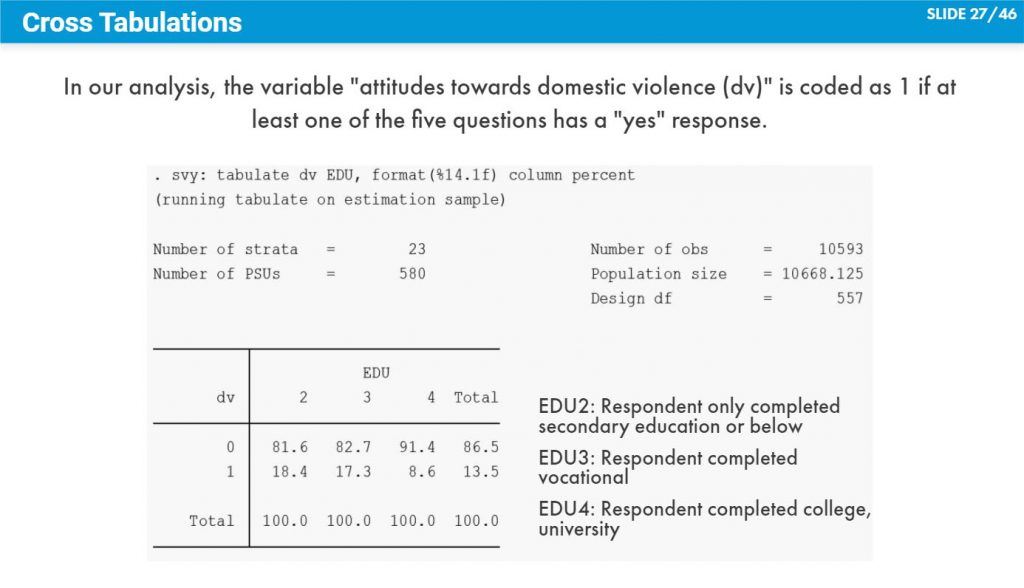
First, it is necessary to prepare the dataset so that it is ready to be read into R or STATA. The response variable (“attitudes towards domestic violence”) needs to be reconstructed. MICS6 has five questions to assess the attitudes towards domestic violence. Namely: “a husband is justified in hitting or beating his wife in the following situations: (1) she goes out without telling him, (2) she neglects the children, (3) she argues with him, (4) she refuses to have sex with him, (5) she burns the food.”
The same questions were asked to both women and men. In order to turn these five questions into a single variable with dichotomous values (yes or no), the response variable (“attitudes towards domestic violence”) is coded as 1 if at least one of the five questions have a “yes” response and coded as 0 only if all five questions have “No” as responses. This step is needed to perform the logistic regression.

When working with a dataset, one needs to carefully consider the missing observations. If these are occurring at random, we might consider excluding them without worrying too much that this will lead to biased estimations. However, most data are not missing at random. For example, if women from a local ethnic group have high non-response rates in a survey due to systematic discrimination against them in education or in other social aspects, then the missing values would occur more often for women of this ethnic group. This severely weakens the representativeness of the survey and can introduce bias.
If the missing values are not at random and are frequent, then simply removing the observations produces biased estimates. In this case, advanced statistical techniques might be needed to impute the missing data, which is beyond the scope of this module. Preparing the data for statistical analysis might be tedious and challenging work, but this important step is too often overlooked.
It’s always a good practice to explore the general structure of the data before performing any advanced statistical analysis. Do place of residence (urban or rural) and wealth have any relationship? If there is a pattern between them, is it a positive or a negative relationship? Correlation is a useful numerical summary of the strength of a relationship between two variables. Correlation ranges from -1 to 1.

When performing statistical analysis to sample survey data, in most cases, the data must be weighted. This is because the overall probability of selection of each household is not a constant. Simple weighting might be enough when doing simple tabulation on an indicator (e.g. sum of male or female). However, for any analysis that involves the estimation of standard errors, confidence intervals, or significance testing, it is important to consider the complex sample design parameters, such as the primary sampling units (PSUs), the stratification variable, and the sampling weights.
Many types of regression analysis can be used depending on the types of dependent variables. Categorical scales are very common in household surveys, such as MICS6. The response and explanatory variables considered as an illustration in this module are all categorical – except for age which is a continuous variable. A standard linear regression model is not suitable for analyzing response variables with categorical scales. We will use logistic regression because our response variable is a categorical variable that has a measurement scale consisting of a set of categories (yes or no) instead of a continuous response variable.
Logistic regression can be used to predict the value of a dependent variable, which is the probability of success (π), ranging between 0 and 1, that a given outcome will occur.
eLearning Module 7: Multi-Level Disaggregation Analysis to Monitor the SDGs from a Leave No One Behind Perspective
The learning goals of this module are:
- Learn how the multi-level disaggregation analysis is used to monitor the SDGs from a Leave No One Behind (LNOB) perspective.
- Understand how to apply the LNOB Analysis Methodology.
- Know how to test the significance of LNOB results.

To identify populations furthest behind, LNOB analysis focuses on disaggregating data by sex and other variables simultaneously. The first step to conducting this analysis should be identifying which variables should be used for disaggregation. To achieve this, it is important to look at multiple contextually relevant socio-economic characteristics that can be potential causes or drivers of inequality in each country. An individual can be at the intersection of multiple identities that push them behind on the ladder of progress.

Four key steps are necessary to undertake multi-level disaggregation analysis to assess SDG progress from the LNOB perspective:
- Get the right data
- Select disaggregation variables
- Conduct analysis
- Use the results
Microdata is necessary to conduct this type of analysis. It is important to utilize survey or census data to be able to generate aggregates for all population groups of interest.
It is important to identify the research questions. For example, “What are the population groups that are lagging behind?” or “According to which development indicators do they lag behind?” If this analysis is being conducted to inform the monitoring of national policies and priorities, it is important that these questions are answered utilizing national strategies or similar documentation.
UN ESCAP’s Every Policy Is Connected (EPIC) tool provides practical guidance for the identification of development indicators in line with national priorities:
- Hold multi-stakeholder consultation.
- Content analysis of gender-relevant policy documents to identify priority issues and target groups.
- Map with existing indicators at national/regional/global levels.
- Conduct a conceptual framework analysis.
The selection of the target population (e.g. sex, age group, etc.) should be made based on policy priorities and indicator metadata when using existing indicators. Prior to proceeding with the calculations, however, it is important to take into account the sample size and sampling design of existing data sources. To calculate the proportion of women aged 18-49 who are underweight, the following information is required:
- Microdata
- Statistical analysis software such as STATA, SPSS, SAS, or R
- Indicator Metadata
- Survey Metadata

There are many forms of sampling design (e.g. simple random sampling, stratified random sampling, etc.). DHS uses a 2-stage cluster sampling procedure.
Stratification is the process of grouping PSUs into strata, i.e. homogeneous subgroups (such as urban vs. rural or geographic region). In the case of stratified sampling, strata are selected first, and households within each stratum are selected at a second stage.
A sampling weight is a number that is multiplied by each observation (e.g. each response from a woman, child, household, etc. depending on the questionnaire) to weight-up or weight-down that observation if under-or-over-sampled. Weights must always be used when conducting a survey data analysis. These weights vary depending on the unit of analysis. In the case of DHS, some of the available weight variables are listed on the slide.
After all these elements are well understood, the analyst can proceed with all the stages of LNOB analysis:
Part 1: Computing the indicator of interest.
Part 2: Disaggregating the variable by multiple socio-economic factors relevant in the national context.
Part 3: Comparing groups lagging behind across multiple indicators.
Part 4: Identifying the total population that lags behind consistently across multiple indicators.
After selecting the indicators of interest and understanding their metadata, the first step is to calculate each of the indicators for the total population.
If you’ve gotten this far in the analysis, you should have already checked which socio-economic factors are relevant and could be potential drivers of inequality. These will be used as disaggregation variables.
To show how different population groups perform regarding different development outcomes, the next step is to disaggregate each of the development indicators utilizing some of these socio-demographic variables. Let’s take a look at some of the more common disaggregation variables that are often drivers of discrimination and therefore deprivation for women.
After calculating all indicators of interest, the analyst should perform disaggregation at various levels (e.g. by location, wealth, ethnicity, etc.) to identify the population groups furthest behind for each indicator. To identify the total share of the population with multiple deprivations, it is important to see who experiences deprivations for more than one indicator. In our example, we look at the proportion of the population that experiences deprivation in three areas (using three indicators). To ensure comparability across indicators, we must ensure all indicators considered utilize the same age group.
In order to properly monitor the SDGs and meet the promise of Leaving No One Behind, data disaggregation at multiple levels must become common practice and must be included in routine monitoring of progress.
eLearning Module 9: Finding the Right Gender Data and Conducting Basic Analysis
This module aims to:
- Explain how to select statistical data that is relevant, coherent, comparable, accurate, reliable, and timely.
- Teach to source and use macrodata as well as microdata from various online resources.
- Demonstrate how to perform the basic steps of gender data analysis using data from various sources.

Gender data can be used to track progress for men and women in a given country or region, hold governments accountable, and help policymakers make informed decisions to enhance the lives of women and men. Gender data can also be a powerful tool for advocacy and to conduct research to improve people’s lives. It is therefore very important that the data used by policymakers, advocates, scientists, and journalists are of good quality. It is also important that the user is aware that not all data are good data. The one key characteristic of good data is that data must be gender-sensitive or, in other words, must reflect a gender perspective across all relevant issues.

According to the UN Statistical Quality Assurance Framework (SQAF), a good statistical output should be:
- Relevant
- Coherent
- Comparable
- Accurate
- Reliable
- Timely
- Accessible
- Interpretable
So, which data source is better? This depends on your research question, the type of research you want to do, the scope of your research, and your level of statistical literacy. However, there is one general recommendation for all data users: prioritize official statistics over non-official statistics whenever possible.
Macrodata refers to national aggregates or data that are available for a higher-level unit (for example, a group). Macrodata are constructed by combining information for the lower-level units, of which the higher-level unit is composed (for example, individuals within the group). Generally, when looking at a data point that is representative of a whole country, such as GDP, we are looking at macrodata. Other examples of such aggregate data include summaries of population characteristics, economic measures such as unemployment statistics, population prospects, etc. You should choose to use macrodata when looking for national-level estimates or when looking for readily available estimates representative of a country or select groups within the country. For instance, the primary enrolment rate for girls in a certain country is an example of macrodata. It is calculated by aggregating individual-level information on whether or not each girl of a certain age group is enrolled in school.
The sources of gender-relevant macrodata include:
Microdata can generally be described as individual-level data, whereby a data point is available for each household or individual within each household. If presenting a microdata set in the form of a two-way table, each row typically represents an individual person or a household and each column – a variable such as age, sex, or job type. Most countries analyze and process their microdata to obtain national aggregates or macrodata estimates. However, microdata can be useful for users to conduct further analysis, including assessing how strongly two different variables are associated through correlations or regressions. Microdata is also useful for modeling and forecasting. Finally, working with microdata is also key to calculating gender indicators for specific population groups. As most macrodata published is representative of a whole country or large population groups within the country, microdata might be necessary to calculate estimates for specific population groups.
The sources of gender-relevant microdata include:
- DHS (Demographic and Health Surveys) STATcompiler
- IPUMS International and IPUMS Tabulator
- Household Surveys for Gender Data Analysis
- DHS and MICS Datasets
- National Statistics Offices
- Other national sources of gender data

Analyzing gender data can be a complex process in which individual-level records are processed through statistical software, such as SPSS or Stata to assess the results from a gender perspective. Or it can be a much simpler process through which macrodata for gender-relevant indicators is directly downloaded and comparisons are carried out across countries, between indicators, and over time. Analysis of gender data is the process used to obtain data-informed responses to relevant research questions. Generally, the following steps should be followed to perform data analysis:
- Step 1: What is the research question?
- Step 2: What information is already available?
- Step 3: Can pre-processed data be used?
- Step 4: What’s the right source of data to conduct additional analysis?
The method of analysis varies depending on the data source and type of data.
eLearning Module 10: Communicating Gender Data
After completing this module, the learners are able to:
- Facilitate the user-producer dialogue to improve gender data communication.
- Use various channels for communicating gender data, including databases, repositories, reports, factsheets, and media.
- Communicate data visually by utilizing charts, graphs, icons, typography, and other building blocks of effective visual communication.
Data communication and dissemination are different concepts. Although they are often used interchangeably, it is important that you understand the differences.
Data dissemination occurs when the data collected and compiled by statistical agencies are released to users. While these data may be made available to users, they may not always align with the users’ needs, (for instance, data might be shared in a complex manner, such as through a database instead of a publication, or may be shared in a format that is not preferred by the user, such as print instead of digital). As a result, the available data are often underused. This, in turn, can lead to data waste.
Data communication, on the other hand, is the strategic outlining and delivery of key data-driven messages using relevant media formats and communications channels to best target identified audiences. In other words, data communication helps align the demand and supply of data products. Without data communication, there is little data use and large amounts of data waste. Read both definitions on this slide before moving on.
A typical communication cycle consists of the following steps:
- Dialogue between users and producers to identify data needs and desired formats.
- Data production.
- Data analysis in coordination with the users.
- Generation of reports, infographics, media products, etc.
- Communication of findings and dissemination of products.
Data producers often disseminate gender data, but rarely communicate it. For instance, data produced by statistical agencies are often released to the public through databases and survey reports which may not be suitable for all types of potential data users. Decision-makers, non-statistical experts, and the general public may have different data needs and thus will prefer different data formats and channels. Effective communication strategies can substantially increase the use of gender data, particularly among non-expert users.
A communication strategy helps to define clear priorities, identify target audiences, create appropriate key messages, and choose the right communication channels around an overarching goal. An effective data communication strategy should include specific actions to reach all potential types of users through different communication formats and channels. It should consist of separate sections for different target audiences. The design of gender data communication strategies must be informed by user-producer dialogues which must happen at two stages: before and after the data are produced.
Examples of channels or media of communication include websites and data portals. Examples of products include reports and infographics. It is important to tailor the selection of communication channels and products to potential users and their needs.
A report is the most common channel of communication between data users and data producers. Reports organize and synthesize data that span in many forms, from tables to summary text. Statistical reports typically focus on presenting the findings of surveys or other data collection exercises and can vary in their focus, level of detail, and utilization of visual elements. In addition to presenting findings, survey reports should describe the survey methodology, providing information on survey design, data collection process, strengths and limitations, a copy of the questionnaire used, etc. This information is important to be able to assess the reliability of findings and to interpret the data correctly.
Long pieces of text can be boring and seem monotonous to readers. A general recommendation on using data visualizations for statistical reports is to replace or complement text and tables with visuals where possible and appropriate. Infographics are very beneficial in presenting data and are often a recommended data visualization technique. But be cognizant of providing adequate descriptions as well. Visuals without accurate descriptions can be challenging to interpret and can lead to misinterpretation. You should ensure that graph titles are clear, comprehensive, and accurate.
Visuals are important for an effective media story. Here are some general recommendations on using data visualization for written media stories:
- Include graphs, infographics, and iconography that make the information relatable to the audience.
- Build on the same message by using a different data point and a new data visual to add variety and reinforce the message.
- Keep a coherent color scheme throughout the news article.
- Add authentic, contextually accurate, non-stereotypical, and gender-sensitive images to make the content relatable to the readers.
Gender data and statistics play a core function for journalists who intend to build evidence-based gender stories. Ideally, media engagement should go well beyond press releases on data collection exercises and survey reports. It is more effective to build long-term partnerships with journalists, so data producers can target their statistics and format to the needs and interests of the media and the general public. While statisticians often find it challenging when journalists fail to understand and interpret statistics correctly, the challenges of media personnel often revolve around statistics not being openly accessible, being produced in formats that are difficult to consume, or unavailable altogether for the topic of interest.
eLearning Module 11: Using Gender Data for Policymaking
Here are the learning objectives for this module:
- Understand the importance of data-informed decisions in policymaking.
- Understand the components of the policymaking process and what guides the policymaking decisions.
- Know how to take actions to overcome the barriers to evidence-based decision making.
Policymaking is the practice of making tangible written rules that govern a group of people or society at large. The policymaking process includes a wide range of activities. In some cases, these might start with identifying policy issues, followed by gathering the necessary evidence to understand these issues fully. In others, data analysis might actually be the first step, revealing inequalities or other concerns and policymaking follows as a result. Either way, data should play a central role in policy formulation. Making data-informed decisions helps promote policy effectiveness by supporting the creation of targeted responses to issues. Therefore, the quality of statistics and statistical procedures can affect policy outcomes; good statistics lead to good policies and result in better development.
Gender statistics should be used at all stages of policymaking, from identifying the needs and priority policy areas to designing responses to such needs, informing monitoring processes, and advocating to mobilize support for gender-responsive policies. Although no silver bullet exists for policymaking, and the effectiveness of policies depends highly on the country context, the steps shown here can guide policymakers in making informed decisions and formulating responsive policies.
The indicators to monitor policy implementation should align with the policy’s expected outputs, outcomes, and impact. Gender data should be used consistently for those indicators. In practice, this can be achieved by using:
- Indicators disaggregated by sex
- Indicators that capture gender-specific issues even without disaggregation (e.g. maternal mortality ratios, or proportion of households that use clean cooking fuels)
Communication of a policy goal is key to convincing stakeholders to take appropriate action. Communication strategies must be tailored to different groups of stakeholders, their level of expertise, and prior knowledge of gender issues. Most importantly, these strategies must highlight the potential impact of the policy. Gender data can be a powerful tool in communicating these messages, as statistics provide hard evidence of the population’s needs and the impact of policy responses.
Policy implementation should take gender bias into consideration. At the planning stage, contingencies must be put in place to ensure that those in charge of implementation are aware of any potential bias and receive gender-sensitization training as needed. At the implementation stage, adequate monitoring can prevent and help address any existing bias. It is important to use gender data to monitor the pace and results of policy implementation. Often, the use of aggregates (e.g. monitoring with statistics for the total population as opposed to disaggregated data) hides inequalities and potential issues associated with policy implementation that might be affecting only a select population group.
Policy reports must be publicly available and easily accessible in different media and formats. It is important that national statisticians and policymakers collaborate for the production of these reports. As such, statisticians must remain engaged through all steps of the policymaking process: from providing the necessary data to informing decision-making at the design stage, to supporting data production for monitoring and implementation, to producing.
The policymaking process starts with an analysis of the existing situation in the relevant policy area. This is often guided by information from a variety of sources, including insights from experts in ministries, gender focal points, civil society representatives, existing research, and data. The use of existing gender data is essential for understanding the significance of the issue and related needs and challenges for men and women.
The extent to which data guides policymaking decisions depends on how credible the data is and how well it is communicated. It is important that policymakers engage national statisticians, interpret the data correctly, and understand the difference between official and non-official statistics, representative vs. non-representative estimates, and quality vs. non-quality data. It is also important that once identified, the target population groups are consulted to gather evidence that will inform policy formulation.
Once the policy issue has been identified and assessed, empirical research findings can help shape policies.
When planning policies, it is also important to identify indicators to monitor progress. Indicators should be selected based on relevance, in connection with policy outputs, outcomes, and impacts. It is important to refrain from selecting indicators based only on ease of data collection or data availability. When data for relevant indicators are unavailable, advocacy for their production should accompany policy implementation.
Although using gender statistics for making gender-sensitive policies seems like a rather obvious choice, this practice does not take place consistently. This results in policies that aren’t backed by statistics and don’t reflect the realities of the target groups they intend to affect. Reasons may range from misalignment between data availability and data needs to limited analytical skills on the part of users and lack of data communication strategies on the part of producers. Institutionalizing the dialogue between data-producers and policymakers can be a good starting point to addressing this problem.
Here are some recommendations that can help overcome barriers to evidence-based decision-making:
- Policymakers need to understand the value of the evidence, become more informed as to what evidence is available, know how to gain access to it, and be able to critically appraise it.
- Statistical literacy training can be conducted for policymakers to enhance their understanding of gender data and how to use it for policymaking.
- Institutional bridges must be built to strengthen the integration of policy and evidence in a sustainable manner.
- Putting in place discussion forums and joint training and coordination groups can sustain the engagement between data producers and policymakers, leading to an environment where data producers are seen as collaborators rather than ad-hoc suppliers in the policymaking process.
- Data need to be better communicated to facilitate their use in decision-making. This includes making data easily available and understandable to users and communicating them in an engaging way, tailored to the expertise of the audience.
- Incentives must be put in place to encourage the use of evidence. Incentivizing evidence-based policymaking can result in better policies for sustainable development.
eLearning Annex 2: Integrating Survey and Geospatial Information Data for Gender Analysis
This module focuses on:
- Learning how to integrate geospatial information with population data to identify the areas or vulnerable groups that are in the greatest need.
- Learning to extract values from the geospatial datasets and use data to build models that predict the outcome of interest, also known as the dependent variable.
- Gaining a basic understanding of the Random Forests machine learning model, its functionality, and its application.

The monitoring of the goals and targets of the 2030 Agenda for Sustainable Development requires reliable and timely data disaggregated by sex, geographic location, and other socioeconomic characteristics. This has greatly increased the demand for data. With the advancement in Geographic Information Systems (GIS) technologies, more governments are now encouraged to use open-source GIS software (including publicly available geospatial data) to spatially analyze data. This approach can help achieve the data requirements of SDGs.
The statistical community is beginning to understand the benefits and the need for geographic location in conducting statistical analysis. For example, the World Bank has integrated Living Standards Measurement Survey data and geospatial information to create poverty maps in several countries. The poverty maps are useful tools to visualize and compare poverty rates across geographic areas (district and subdistrict levels) disaggregated by sex. By integrating geospatial information with population data, reliable and granular data can be visualized to identify the areas or vulnerable groups in the greatest need.

The integration of survey and geospatial data can provide powerful insights, particularly related to the environment. Integrating georeferenced disaster data with disaggregated socio-economic data can provide useful inputs to evidence-based policymaking and effective disaster management.
For illustration purposes, this training module uses microdata from Demographic and Health Surveys (DHS) in Bangladesh and several environment-related geo-covariates that are identified as potentially useful predictors of child marriage. DHS surveys collect GPS location data of surveyed clusters. The coordinates of each cluster, along with other geographic information, are stored in the GIS shapefile. The shapefiles in the DHS survey allow us to link the values of the geo-covariates by each cluster in DHS surveys. The shapefiles are available upon request for download through the DHS program website, following the application of geospatial displacement on the GPS cluster data to protect the confidentiality of respondents.

Many of the GIS data are stored in two data formats called “vector” and “raster”. The shapefile format in the DHS Bangladesh 2014 is a vector data format, which defines the boundaries and shape of clusters in DHS. Vector data are represented by points (e.g. sampling locations, individual trees), lines (e.g. roads, streams), and polygons (e.g. lake, oceans).
The GIS data format of geo-covariates used in this module is a raster data format. Raster or “gridded” data are stored as a grid of values that are rendered on a map as pixels. Each pixel value represents an area on the Earth’s surface. Raster data can be continuous or categorical. Continuous raster format data files can have a range of quantitative values (e.g. population density, poverty index measuring the likelihood of living in poverty per grid square). We can extract values from raster-format data and lay them on the vector data format for visualization purposes.
The ultimate goal of the data integration exercise in this module is to extract statistical values stored in the raster file and link them to the respective cluster locations stored in the DHS shapefile, which is a vector format data. For both the shapefile and the raster data file, a coordinate reference system maps each point/pixel to a precise location on earth. In the shapefile, it is called “proj4string”, and in the raster file, it is called “coord. ref.” The “proj4string” in the shapefile and “coord. ref.” information in the raster file should be the same in order to project the statistical values onto a correct location in the DHS shapefile. After we extract the statistical values of geo-covariates stored in the raster files, we need to merge them with DHS survey data.

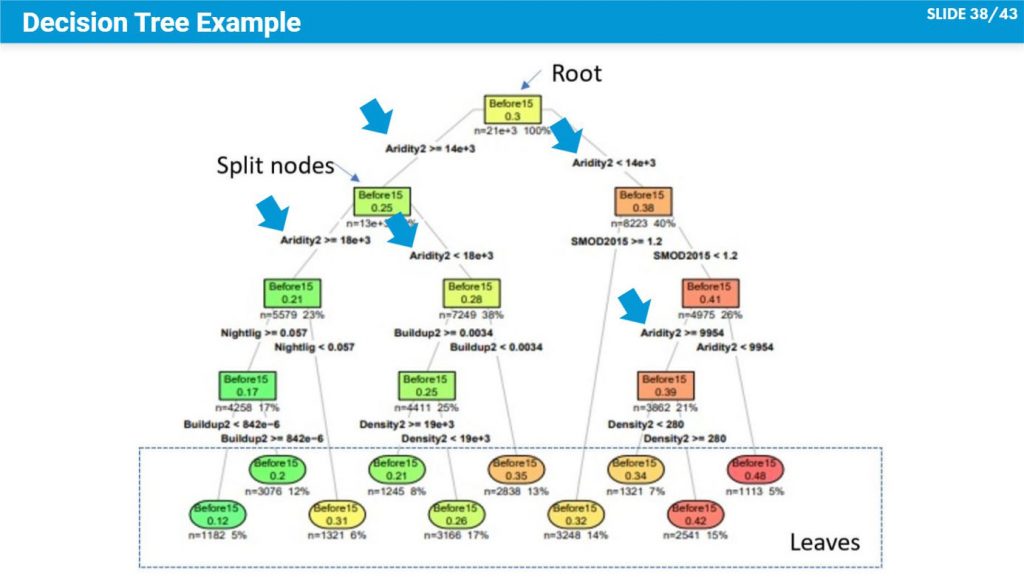
Logistic regression is a traditional statistical method that enables the estimation of the coefficients and the significance of independent variables in the model. It allows us to understand how the change in independent variables impacts the dependent variable of our interest. We can also perform hypothesis-testing based on well-established statistical theories. Logistic regression is also capable of predicting the probability of the dependent variable based on independent variables.
Unlike logistic regression models, Random Forests is a prediction-focused model, it does not provide significance statistics (such as coefficients, p-value, etc.). Its primary interest is to increase the accuracy of the predicted outcome using the given input data. The process of how the model transforms inputs into outputs is, to most non-experts, a black box. Nevertheless, we can get a general idea of which variables used in the Random Forests predictive models are significant in predicting the outcome.
eLearning Course Summary
All SDG indicators need to be considered as an integrated package and must work in harmony with one another. Many important issues, such as gender equality, health, sustainable consumption and production, and nutrition, cut across goals and targets. The goals and targets are themselves interdependent and must be pursued together since progress in one area often depends on progress in other areas. As a result, many indicators contribute to monitoring more than one target. An SDG indicator and monitoring framework must also give careful thought to tracking cross-cutting issues so that it can support integrated, systems-based approaches to implementation.

